





한국인이 자주 걸리는 질병 유전정보를 한눈에 보는 웹 포털이 구축된다. 유전자 변이정보뿐만 아니라 전문가가 질병과의 연관성까지 분석한 주석을 제공하는 `유전자 웹 백과사전`이다.
서울대병원은 연말까지 4대 중증질환을 포함해 한국인이 자주 걸리는 질환 관련 유전체 변이 지식정보 데이터베이스(DB)를 구축한다고 7일 밝혔다.
국민 5000명을 대상으로 질환과 연관되는 유전체 변이 빈도도 조사해 직접적인 상관관계도 파악한다. 대상 질환은 암, 심장병, 뇌질환, 희소난치성 질환 4대 중증질환과 한국인이 자주 걸리는 질병이다.
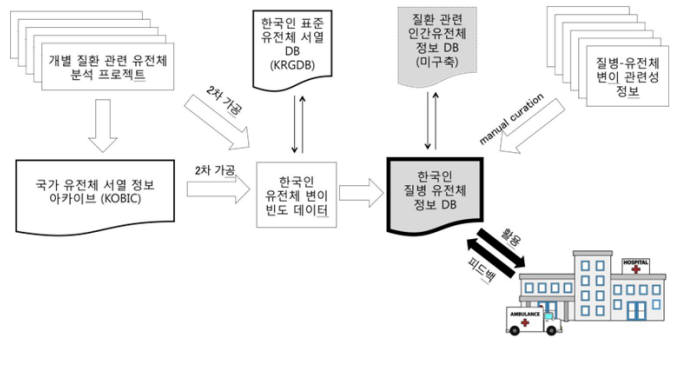
우선 질병관리본부, 국립보건연구원 등이 보유한 유전체 정보를 분석해 유전체 변이와 질병의 연관성을 파악한다. 서울대병원을 중심으로 질환별 전문가와 유전체 전문가가 참여한다. 유전체 변이 및 질병과 관련성이 증명된 변이자료(코드 그린), 질병과 연관성이 의심되나 검증되지 않은 자료(코드 옐로우), 질병과 연관성에 대한 논란이 많아 주의가 필요한 변이자료(코드 레드) 등으로 나눠 DB화한다.
김종일 서울대의대 교수는 “유전체 분석 중요성은 커지고 있지만 의사조차도 관련 정보나 지식을 얻기 쉽지 않다”며 “곳곳에 산재한 유전체 변이 정보를 취합해 발병 빈도를 분석, 의사나 일반인에게 연관성을 제공하는 게 목표”라고 말했다.
한국인이 자주 걸리는 질병과 유전자 변이 상관관계를 수치화한다는 점에서 의미가 있다. 가령 브라카원(BRCA1)은 유방암을 유발하는 유전자로, 미국 영화배우 앤젤리나 졸리가 이 유전자를 보유해 예방 차원에서 유방 절제술을 받았다. 하지만 브라카원 유전자를 보유했다고 해서 모두 유방암에 걸리거나 예방을 위해 유방 절제술을 받을 필요는 없다. 유전자와 질병 발병 빈도를 수치화하고 유전체 전문가가 이에 대한 해석을 제공할 때 의료진은 명확한 진단을 위한 정보를 얻을 수 있다.
산재한 유전정보를 특정 목적에 맞게 DB화한다. 우리나라는 유전체 서열 정보 DB(KOBIC), 질환 관련 인간 유전체, 단백질 지식정보 DB 등이 구축돼 유전체 연구에 활용된다. 하지만 KOBIC는 사람부터 동식물에 이르는 모든 유전체 정보가 해당되며, 원본 데이터를 효율적으로 보관하는 데 초점을 둔다. 데이터를 가공하거나 특정 목적에 맞게 정제하는 작업은 거의 이뤄지지 않는다.
질환 관련 인간유전체 및 단백질 지식정보 DB 역시 한국인 표준 유전체 서열만 공개한다. 해외에서는 `1000 게놈 브라우저` `클린바(ClinVa)` 등을 통해 세계인을 대상으로 유전체 변이 빈도 수, 질병 유발 등을 DB화해 홈페이지에 공개한다. 다양한 인종이 대상이지만 한국인은 포함되지 않는다.
조대연 랩지노믹스 연구소장은 “우리나라에서도 질병 관련 유전체 분석 시도가 활발하지만 체계적으로 취합되거나 정리되지 않았다”며 “유전체 정보를 제대로 활용하기 위해 원본 데이터 혹은 연관 데이터와 연계하고 목적에 따라 DB화할 필요가 있다”고 말했다.
정용철 의료/SW 전문기자 jungyc@etnews.com

