







구글 번역 연구팀이 발표한 리포트에 따르면, 번역 전문 인공지능 모델 '트랜스레이트젬마(TranslateGemma)'가 무료로 공개됐다. 이 모델은 55개 언어의 번역 품질을 크게 높였으며, 놀랍게도 작은 크기의 모델이 큰 모델만큼 또는 더 나은 성능을 보였다. 이는 적은 컴퓨팅 자원으로도 고품질 번역이 가능하다는 의미로, AI 번역 기술의 효율성을 한 단계 끌어올린 것으로 평가받는다.
두 번의 학습으로 번역 실력 키워... AI가 만든 데이터와 사람 번역 데이터 결합
트랜스레이트젬마는 구글의 젬마 3 모델을 기반으로 두 차례의 추가 학습 과정을 거쳐 번역 능력을 강화했다. 첫 번째 단계에서는 AI가 만든 번역 데이터와 사람이 직접 번역한 데이터를 섞어서 학습시켰다. 구글은 각 언어마다 최대 1만 개의 번역 예제를 만들었는데, 이 과정에서 제미나이 2.5 Flash라는 AI 모델을 사용했다.
AI가 번역 데이터를 만드는 과정은 꽤 정교하다. 먼저 원문 하나당 128개의 번역 결과를 만든 다음, 그중에서 가장 품질이 좋은 것만 골라냈다. 이렇게 만든 번역 데이터는 짧은 문장부터 긴 문단까지 다양한 길이를 포함했다. 세계 번역 품질 평가 대회인 WMT24++가 다루는 모든 언어와 추가로 30개 언어에 이 방법을 적용했다.
영어나 중국어처럼 많은 사람이 쓰는 언어 외에도 스와힐리어나 마라티어처럼 상대적으로 적은 사람이 쓰는 언어의 번역 품질도 높이기 위해 노력했다. 이를 위해 사람이 직접 번역한 자료를 추가로 활용했다. SMOL이라는 자료 모음에는 123개 언어가, GATITOS라는 자료 모음에는 170개 언어가 담겨 있어 모델이 훨씬 더 다양한 언어를 배울 수 있었다.
또 한 가지 중요한 점은 이 모델이 번역만 잘하는 것이 아니라 질문에 답하기, 글쓰기 같은 다른 일도 잘할 수 있도록 만들었다는 것이다. 그래서 학습에 사용한 전체 자료 중 30%는 번역이 아닌 일반적인 대화나 작업을 수행하는 자료로 채웠다.
5개의 평가 도구로 번역 품질 한층 더 높여
두 번째 단계에서는 강화학습이라는 방법을 사용했다. 쉽게 말해, 여러 개의 '평가 선생님'을 두고 번역 결과가 얼마나 좋은지 계속 평가받으면서 실력을 키우는 방식이다. 구글은 다섯 가지 평가 도구를 동시에 사용했다.
첫 번째 평가 도구인 MetricX는 번역 품질을 0점(최고)부터 25점(최악)까지 점수로 매긴다.
두 번째로는 기계 번역 품질을 평가하는 모델 AutoMQM을 사용해서 번역에서 어떤 부분이 잘못되었는지 구체적으로 찾아낸다. 이 도구는 2020년부터 2023년까지의 세계 번역 품질 평가 데이터로 학습되었다.
세 번째 ChrF는 원문과 번역문의 단어가 얼마나 비슷한지 비교한다.
네 번째는 '자연스러움 평가기'로, 번역된 문장이 원어민이 쓴 것처럼 자연스러운지 판단한다.
마지막으로 추론 능력, 지시 수행, 다국어 능력 등 여러 작업을 평가하는 종합 평가 도구도 사용했다. 이렇게 다섯 개의 평가 선생님이 동시에 피드백을 주면서 모델의 번역 실력을 계속 향상시켰다.
모든 크기의 모델에서 번역 품질 20% 이상 향상
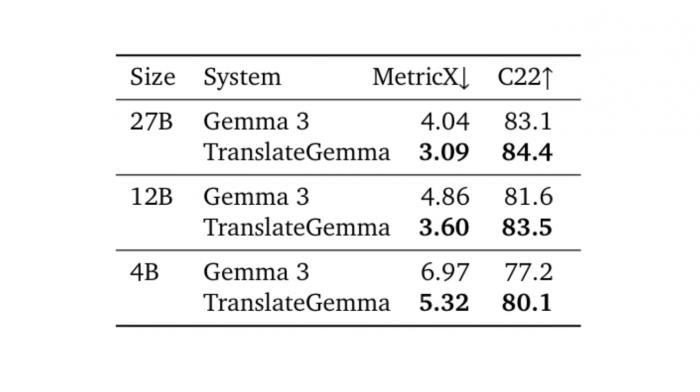
트랜스레이트젬마는 55개 언어 번역을 평가하는 WMT24++ 테스트에서 검증받았다. 가장 큰 270억 개 규모 모델의 경우 평가 점수가 4.04에서 3.09로 낮아졌다. 점수가 낮을수록 번역 품질이 좋다는 의미이므로, 약 23.5%나 개선된 셈이다. 120억 개 규모 모델은 4.86에서 3.60으로 25.9% 개선되었고, 40억 개 규모 모델은 6.97에서 5.32로 23.6% 개선되었다.
다른 평가 지표인 Comet22에서도 비슷한 결과가 나왔다. 이 지표는 학습 과정에서 직접 사용하지 않았는데도 점수가 올랐다는 점이 의미 있다. 120억 개 규모 모델은 81.6에서 83.5로 점수가 올랐고, 40억 개 규모 모델은 77.2에서 80.1로 더 큰 폭으로 상승했다.
가장 놀라운 발견은 작은 모델이 큰 기존 모델과 비슷하거나 더 나은 성능을 보였다는 점이다. 120억 개 규모 트랜스레이트젬마 모델은 270억 개 규모의 기본 젬마 3 모델보다 번역을 더 잘했다. 마찬가지로 40억 개 규모 트랜스레이트젬마 모델은 120억 개 규모 기본 모델과 비슷한 수준의 번역 품질을 보였다. 이는 더 적은 컴퓨터 자원으로도 높은 품질의 번역이 가능하다는 것을 의미한다.
독일어부터 아이슬란드어까지 모든 언어에서 번역 품질 향상
55개 언어별로 자세히 살펴본 결과, 트랜스레이트젬마는 모든 언어에서 일관되게 번역 품질이 좋아졌다. 많은 사람이 사용하는 언어들의 경우, 영어-독일어는 1.63에서 1.19로, 영어-스페인어는 2.54에서 1.88로 개선되었다. 영어-히브리어는 3.90에서 2.72로 향상되었다.
사용자가 적은 언어들에서는 개선 폭이 더욱 컸다. 영어-스와힐리어는 5.92에서 4.45로, 영어-리투아니아어는 6.01에서 4.39로, 영어-에스토니아어는 6.40에서 4.61로 좋아졌다. 특히 영어-아이슬란드어의 경우 8.31에서 5.69로 크게 향상되어, 사용자가 적은 언어에서도 모델이 번역을 잘한다는 것을 보여주었다.
연구팀은 270억 개 규모 모델이 학습 과정에서 더 많은 언어를 접해서 더 많은 이점을 얻었을 것으로 보고 있다. 실제로 학습 단계에서는 수백 개의 언어가 사용되었으며, 영어와 쌍을 이루는 언어부터 영어를 포함하지 않는 언어 조합까지 다양하게 포함되었다.
이미지 속 글자도 번역 가능... 별도 학습 없이도 능력 유지
트스레이트젬마는 텍스트 번역 능력이 향상되면서도 이미지 속 글자를 번역하는 능력도 그대로 유지했다. Vistra라는 이미지 번역 평가에서 이 능력을 확인했다. 흥미로운 점은 이미지 관련 학습 데이터를 전혀 사용하지 않았다는 것이다.
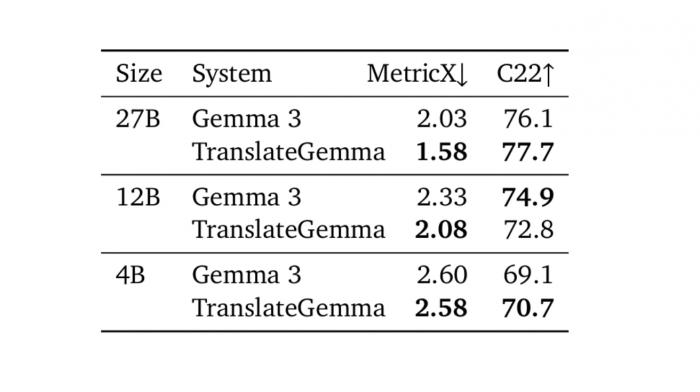
평가를 위해 글자가 하나만 있는 264개의 이미지를 선택했다. 모델에는 이미지와 "이 글자를 번역해주세요"라는 요청만 주었고, 글자가 이미지 어디에 있는지나 미리 글자를 인식한 결과 같은 추가 정보는 주지 않았다. 영어를 독일어, 스페인어, 러시아어, 중국어로 번역한 평균 점수를 측정한 결과, 270억 개 규모 모델은 평가 점수가 2.03에서 1.58로 거의 0.5포인트 개선되었다.
120억 개 규모 모델도 2.33에서 2.08로 0.25포인트 좋아졌다. 40억 개 규모 모델은 용량이 작아서인지 69.1에서 70.7로 작은 개선만 있었다. 이러한 결과는 텍스트 번역 실력이 좋아지면 이미지 속 글자 번역 능력도 자연스럽게 향상된다는 것을 보여준다.
사람이 직접 평가해도 대부분 언어에서 우수한 성능
자동 평가 외에도 전문 번역가들이 직접 번역 품질을 평가했다. 번역가들은 번역된 문장에서 잘못된 부분을 찾아 표시하고, 얼마나 심각한 오류인지 분류했다. 평가는 영어에서 한국어를 비롯한, 독일어, 중국어, 이탈리아어, 세르비아어, 스와힐리어, 마라티어로의 번역 등 10개 언어 조합에서 진행되었다.
전 세계에서 많이 쓰이는 언어와 상대적으로 적게 쓰이는 언어를 골고루 섞었고, 다양한 언어 계통과 문자 체계도 포함했다. 평가 자료는 세계 번역 품질 평가 대회 WMT25의 문학, 뉴스, 소셜미디어 분야에서 가져왔다. 모든 언어 조합에 대해 트랜스레이트젬마 120억 개와 270억 개 규모 모델, 그리고 기본 젬마 3, 270억 개 규모 모델을 비교했다.

결과는 대부분의 언어 조합에서 사람이 평가해도 트랜스레이트젬마가 기본 젬마 3보다 확실히 나았다. 다만 두 가지 예외가 있었다. 독일어로 번역할 때는 두 모델이 비슷했고, 일본어에서 영어로 번역할 때는 트랜스레이트젬마가 오히려 성능이 떨어졌다. 자세히 살펴보니 사람 이름이나 지명 같은 고유명사를 잘못 번역한 것이 원인이었고, 다른 종류의 오류는 줄어들었다.
트랜스레이트젬마의 개선 효과는 사용자가 적은 언어 조합에서 특히 두드러졌다. 영어-마라티어는 1.6포인트 좋아졌고, 영어-스와힐리어나 체코어-우크라이나어는 1.0포인트 개선되었다.
한국어의 경우 흥미로운 결과가 나왔다. 자동 평가에서는 270억 개 규모 모델이 3.43에서 2.81로, 120억 개 규모는 3.79에서 2.97로, 40억 개 규모는 4.72에서 3.93으로 모두 개선되었다. 하지만 전문 번역가가 직접 평가했을 때는 270억 개 규모 모델만 3.8에서 3.1로 개선되었고, 120억 개 규모 모델은 4.6으로 오히려 기본 모델(3.8)보다 성능이 떨어졌다. 일본어→영어에서도 비슷한 현상이 나타난 것으로 보아, 동아시아 언어에서는 자동 평가와 실제 번역 품질 사이에 차이가 있을 수 있음을 보여준다.
사람이 평가한 결과도 자동 평가처럼 270억 개 규모 모델이 120억 개 규모보다 더 나았다. 하지만 120억 개 규모 모델도 많은 사람이 사용하는 언어에서는 더 큰 기본 모델과 충분히 경쟁할 만한 수준이었다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. 트랜스레이트젬마는 기존 번역 AI와 뭐가 다른가요?
A. 트랜스레이트젬마는 구글의젬마 3 모델에 번역을 위한 특별한 학습을 두 번 더 시킨 모델입니다. AI가 만든 번역 데이터와 사람이 직접 번역한 데이터를 섞어서 학습한 뒤, 다섯 가지 평가 도구로 계속 피드백을 받으면서 번역 품질을 높였습니다. 55개 언어 번역에서 일관되게 성능이 좋아졌고, 작은 크기의 모델도 큰 기본 모델만큼 잘 번역해서 효율적입니다.
Q2. 어떤 언어들의 번역이 가장 많이 좋아졌나요?
A. 많은 사람이 사용하는 영어-독일어, 영어-스페인어뿐만 아니라 사용자가 적은 영어-아이슬란드어, 영어-스와힐리어, 영어-리투아니아어 등에서 큰 개선이 있었습니다. 특히 사용자가 적은 언어에서 개선 폭이 더 컸으며, 전문 번역가가 직접 평가한 결과에서도 영어-마라티어가 1.6포인트, 영어-스와힐리어가 1.0포인트 좋아지는 등 우수한 결과를 보였습니다.
Q3. 트랜스레이트젬마로 이미지 속 글자도 번역할 수 있나요?
A. 네, 가능합니다. 트랜스레이트젬마는 텍스트 번역 능력이 좋아지면서 이미지 속 글자를 번역하는 능력도 그대로 유지하고 있습니다. 이미지 번역 평가에서 270억 개 규모 모델의 경우 평가 점수가 0.5포인트 가까이 개선되었습니다. 이미지 관련 학습 데이터를 별도로 사용하지 않았는데도 텍스트 번역 개선 효과가 이미지 번역으로도 이어진 것입니다.
해당 기사에 인용된 리포트 원문은 구글 블로그에서 확인 가능하다.
리포트명: TranslateGemma Technical Report
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. (☞ 기사 원문 바로가기)
AI 리포터 (Aireporter@etnews.com)

