






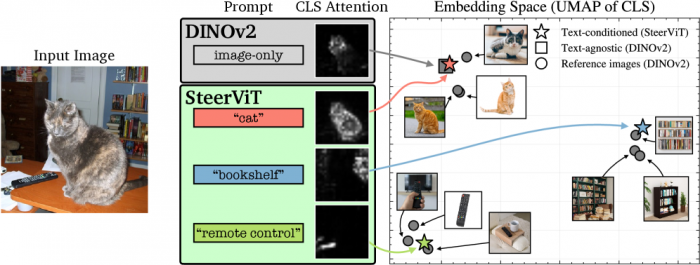
AI에게 거실 사진을 보여주면 소파나 TV보다 고양이를 먼저 알아본다. 눈에 띄는 것만 골라 보는 것이 지금까지 AI 시각 모델의 한계였다. 뉘른베르크 공과대학교(University of Technology Nuremberg)와 카네기멜론대학교(Carnegie Mellon University) 연구진은 2026년 4월 arXiv에 발표한 논문에서 이 문제를 언어로 푸는 새로운 방법 '조종 가능한 시각 표현(Steerable Visual Representations)', 즉 스티어비트(SteerViT)를 공개했다. 이 기술은 AI가 사진 속에서 사용자가 원하는 물체를 골라 집중하도록 텍스트 한 줄로 유도하며, 제조 현장 결함 탐지부터 개인 맞춤형 사진 검색까지 폭넓게 적용될 수 있다.
사진작가가 만든 편견, AI가 물려받다
AI 비전 모델이 고양이만 집중하는 이유는 학습 데이터 때문이다. 사람들이 사진을 찍을 때는 자연스럽게 가장 중요한 피사체를 화면 중앙에 배치한다. 연구자들은 이를 '사진작가 편향(photographer bias)'이라 부른다. 수천만 장의 사진으로 학습한 AI는 이 편향을 그대로 흡수해, 배경보다 전면의 주인공 물체에 압도적으로 더 많은 주의를 기울이게 된다.
대표적인 비전 트랜스포머(Vision Transformer, ViT) 모델인 디노브이투(DINOv2)와 메이(MAE)를 예로 들면, 고양이가 있는 실내 사진을 처리할 때 이 모델들은 고양이에 집중하고 배경의 책장이나 리모컨은 사실상 무시한다. 분류나 검색 같은 일반 작업에서는 문제가 없다. 하지만 제조 현장에서 제품 결함을 찾거나, 의료 영상에서 미세한 병변을 탐지하거나, 편의점에서 특정 상품을 추적해야 할 때는 이야기가 달라진다. 이런 상황에서는 눈에 잘 띄지 않는 요소가 오히려 핵심이기 때문이다.
당신이 스마트폰 사진 앱에서 '내 커피잔'을 찾으려 했는데 AI가 고양이만 보여준다면? 그게 지금 대부분의 AI 비전 모델이 처한 현실이다.
텍스트를 이미지 처리 내부에 직접 주입하는 조기 융합
스티어비트가 기존 방법과 다른 핵심은 '조기 융합(early fusion)' 구조에 있다. 대부분의 멀티모달 모델은 이미지를 먼저 완전히 처리한 뒤에야 텍스트와 결합하는 '후기 융합(late fusion)' 방식을 쓴다. 챗지피티(ChatGPT)에 사진을 올리고 설명을 입력하는 방식이 대표적이다. 이때 언어 정보는 시각 처리가 모두 끝난 다음에야 개입하기 때문에, AI가 이미지를 '보는 방식' 자체를 바꾸지는 못한다.
스티어비트는 이 순서를 뒤집었다. 연구진은 기존 비전 트랜스포머의 각 층(layer) 사이에 경량 교차 주의(cross-attention) 층을 추가해, 텍스트 프롬프트가 이미지 처리 초기 단계부터 영향을 미치도록 설계했다. 쉽게 말하면, 누군가 '책장을 봐'라고 속삭이는 상태로 이미지를 처음부터 다시 훑는 것과 같다. 실제로 인지과학 연구에서도 사람은 특정 단어를 미리 들으면 같은 사진에서 시선이 달라진다는 사실이 확인된 바 있으며, 스티어비트는 이 '하향식 주의(top-down attention)' 메커니즘을 AI에 구현했다.
기술적 효율성도 주목할 만하다. 추가되는 학습 가능 파라미터는 2,100만 개뿐이다. 이는 같은 목적을 수행하는 멀티모달 대형 언어 모델(Qwen3-VL 등)이 요구하는 수십억 개 파라미터의 100분의 1 수준이다. 기존 비전 모델의 파라미터는 그대로 동결한 채 새 기능만 최소한으로 추가하는 방식이기 때문에, 스티어비트는 어떤 사전학습된 비전 트랜스포머에도 붙일 수 있는 '플러그인'처럼 작동한다.
96% 검색 정확도, 기존 모델과 비교한 성능 수치
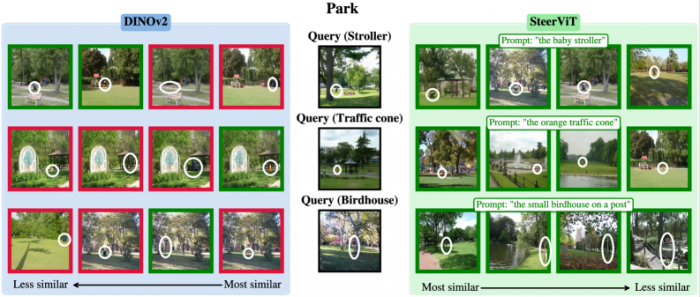
연구진은 스티어비트의 조종 능력을 측정하기 위해 코어(CORE, COnditional REtrieval)라는 새로운 벤치마크를 직접 설계했다. 실내외 6가지 장면(주방, 거실, 화장실, 공원, 주택가 골목, 거리)에서 각각 100장의 사진을 모은 뒤, 각 사진에 5가지 배경 물체를 디지털로 삽입해 총 3,000장의 평가 이미지를 만들었다. 예를 들어 주방 사진에 '올리브오일 병', '과일 바구니', '블렌더'를 각각 삽입한 뒤, AI가 텍스트 프롬프트에 따라 해당 물체가 있는 이미지를 정확히 골라내는지 측정했다.
결과는 명확했다. 디노브이투의 정확도는 44%에 그쳤고, 클립(CLIP)은 44%, 대형 멀티모달 모델인 인턴브이엘쓰리(InternVL3-2B)는 76%를 기록했다. 스티어비트는 96%를 달성했다. 이 차이를 실감하려면 이렇게 생각하면 된다. 같은 작업을 100번 반복할 때 스티어비트는 96번 맞추는 동안 기존 모델은 44번만 맞춘다. 더 중요한 발견은 일반 시각 성능이 훼손되지 않았다는 점이다. 이미지 분류와 의미론적 분할(semantic segmentation) 같은 표준 시각 과제에서도 스티어비트는 기존 디노브이투와 동등하거나 더 나은 성능을 유지했다. 연구진은 이를 '파레토 개선(Pareto improvement)'이라 표현했다. 텍스트 조종 능력을 얻었지만 기존 능력을 잃지 않았다는 의미다.
텍스트 프롬프트를 틀리게 입력하면 어떻게 될까? 실험 결과, 잘못된 프롬프트를 입력했을 때 스티어비트의 정확도는 48%포인트가량 급락했다. 이는 모델이 진짜로 텍스트를 따라가고 있다는 증거이기도 하다.
배운 적 없는 공장 결함도 찾아내는 제로샷 일반화
제로샷(zero-shot) 일반화란 해당 작업에 한 번도 학습하지 않고 바로 적용하는 것을 말한다. 마치 의대를 나온 사람이 처음 보는 증상도 기존 지식을 응용해 진단하듯, AI가 새로운 도메인에 유연하게 대처하는 능력이다.
산업 이상 탐지 벤치마크인 엠브이텍에이디(MVTec AD)에서 스티어비트는 전용 모델들과 경쟁할 만한 성능을 보였다. 이 모델은 ‘이상 부분을 찾아라’ 같은 여러 문장을 함께 활용해(10개 프롬프트 조합) 결함을 찾아냈고, 그 결과 PRO 82.1을 기록했다. 이상 탐지만을 위해 설계된 전문 모델 페이드(FADE)의 84.5와 불과 2.4 차이다. 일상 사진으로만 학습된 모델이 공장 제조 이미지에서 이 정도 성능을 낸다는 것은 상당히 이례적이다.
개인 맞춤형 물체 판별에서도 두드러진다. PODS 벤치마크에서는 '내 머그컵'처럼 특정 개인 소지품을 수많은 유사 물체 중에서 골라내는 능력을 측정한다. 스티어비트에 단순히 '머그컵'이라고만 입력하면 성능이 평범하지만, '검은 테두리의 흰색 에나멜 머그컵'처럼 구체적으로 묘사할수록 성능이 급격히 향상된다. 구체적인 설명을 입력했을 때 분류 정확도는 PR-AUC 기준 58.1%로, 해당 작업을 위해 별도로 파인튜닝된 디노브이투(48.0%)를 앞질렀다. 그것도 100가지 물체 범주마다 별도 모델을 만들어야 하는 디노브이투 방식과 달리, 스티어비트는 모델 하나로 전부 처리한다.
언어로 시각을 조율하는 시대의 시작
스티어비트가 제시하는 방향은 단순한 성능 개선을 넘는다. 지금까지 AI 비전은 '무엇이 보이는가'라는 질문에만 답했다. 스티어비트는 '무엇을 보고 싶은가'라는 질문을 받을 수 있게 만들었다.
실용적 함의는 폭넓다. 전자상거래에서는 '빨간 끈이 있는 흰색 운동화'처럼 속성 조합으로 상품을 검색할 수 있고, 자율주행에서는 상황에 따라 '보행자', '신호등', '이상 물체' 등으로 주의 영역을 실시간으로 전환할 수 있다. 의료 영상에서도 방사선과 의사가 '미세석회화'라고 입력하면 AI가 그 부위에 집중해 분석하는 협업이 가능해질 수 있다.
다만 현 단계의 한계도 분명하다. 스티어비트는 단일 텍스트 프롬프트만 처리하며, '고양이가 없는 곳'처럼 부정형 지시나 여러 조건을 동시에 처리하는 능력은 아직 부족하다. 학습 데이터가 주로 일상적인 사진이어서 위성 영상이나 의료 영상 같은 전문 분야에서는 추가 조정이 필요할 가능성도 있다. 연구진이 차기 과제로 다중 프롬프트 처리와 비디오 분석을 꼽고 있는 만큼, 실제 서비스 적용 속도는 두고 볼 필요가 있다.
그럼에도 이 연구의 핵심 의미는 분명하다. AI가 스스로 결정해온 '볼 것'을 이제는 사람이 언어로 지정할 수 있다. 고양이만 보던 AI가 리모컨까지 찾아주는 시대, 그 시작은 이미 열렸다.
FAQ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q. 스티어비트(SteerViT)와 기존 AI 비전 모델의 차이는 무엇인가요?
기존 모델은 이미지에서 가장 눈에 띄는 물체에 자동으로 집중하지만, 스티어비트는 텍스트 프롬프트를 이미지 처리 초기 단계에 직접 주입해 AI의 시선을 원하는 곳으로 유도할 수 있습니다. 예를 들어 '리모컨'이라고 입력하면 고양이가 있는 사진에서도 리모컨에 집중해 분석합니다.
Q. 실생활에서 어떤 분야에 쓸 수 있나요?
전자상거래의 속성 기반 상품 검색, 제조 현장의 결함 탐지, 의료 영상 내 특정 병변 분석, 개인 사진 앨범에서 특정 물건 찾기 등 다양한 분야에 활용될 수 있습니다. 특히 데이터가 많지 않은 특수 작업에서 추가 학습 없이 바로 적용할 수 있다는 점이 강점입니다.
Q. 프롬프트를 어떻게 써야 더 잘 작동하나요?
연구 결과에 따르면 텍스트가 구체적일수록 성능이 높아집니다. '머그컵'보다 '검은 테두리의 흰색 에나멜 머그컵'처럼 색상, 재질, 특징을 포함한 묘사가 훨씬 정확한 결과를 냅니다. 마치 누군가에게 물건을 찾아달라고 부탁할 때 특징을 자세히 설명할수록 정확히 찾아오는 것과 같습니다.
기사에 인용된 리포트 원문은 arXiv에서 확인할 수 있다.
리포트명: Steerable Visual Representations
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. (☞ 기사 원문 바로가기)
AI 리포터 (Aireporter@etnews.com)

