






매개변수 30억 개짜리 작은 인공지능(AI)이 720억 개짜리 초거대 모델을 이기는 일이 벌어졌다. 비결은 더 큰 두뇌가 아니라, AI가 행동을 결정할 때마다 옆에서 "잠깐, 그게 아니야"라고 짚어주는 검증기 하나를 붙인 것이었다. 독일 다름슈타트 공과대학교(TU Darmstadt)와 헤시안 AI(hessian.AI) 연구팀이 2026년 5월 공개한 논문 '두 번 생각하고, 한 번 행동하라(Think Twice, Act Once)'는 AI 로봇이 자기 실수를 알아차리지 못해 어이없이 실패한다는 문제를 정면으로 다룬다. 본 논문이 제시한 베가스(VeGAS) 기법은 어려운 과제에서 성공률을 최대 36% 끌어올렸고, 모델 크기 경쟁에 매몰된 AI 업계에 새로운 방향을 제시한다.
"스포츠 물건"을 "스폰지"로 착각하는 AI 로봇의 한계
현재 AI 로봇은 익숙한 명령은 잘 수행하지만, 표현이 조금만 바뀌어도 무너진다. 논문에 따르면 AI 로봇은 "바나나를 가져와"라는 명령은 잘 따르지만 "노란 곡선 과일을 가져와"라는 같은 뜻의 명령에는 실패하는 경우가 많다. 연구진이 제시한 실제 사례를 보면 문제의 심각성이 드러난다. "스포츠 물건을 찾아 갈색 탁자에 놓아라"라는 지시를 받은 AI 로봇이 싱크대 옆에 있던 스폰지를 집어 들었다. 스폰지는 스포츠 용품이 아니지만, AI는 이를 인식하지 못하고 행동에 옮긴 것이다.
또 다른 사례에서는 "책을 큰 안락한 휴식 공간으로 옮겨라"라는 지시를 받은 AI가 1인용 안락의자(ArmChair)를 향해 움직였다. 정답은 소파(Sofa)였다. 이런 실수가 발생하는 이유는 AI가 매 순간 가장 그럴듯해 보이는 행동 하나만 떠올린 뒤 곧바로 실행하기 때문이다. 사람이라면 "이게 정말 맞을까?" 한 번 더 생각하고 다른 가능성을 따져보지만, 기존 AI는 그런 검증 과정이 없었다.
베가스(VeGAS)란 무엇인가, 성공률 36% 끌어올린 메커니즘
베가스(VeGAS, Verifier-Guided Action Selection)란 AI 로봇이 행동하기 전에 여러 후보를 떠올리고 별도의 검증 AI가 그중 가장 믿을 만한 것을 골라주는 시스템을 말한다. 작동 방식은 단순하지만 효과적이다. AI 로봇이 매 순간 16개의 후보 행동을 만들어내면, 검증 AI가 각각의 행동에 대해 "이게 맞는 선택인가"를 5번씩 평가한다. 점수가 가장 높은 행동만 실제로 실행된다.
이 방식은 사람의 사고 과정과 닮았다. 사람은 새로운 상황에서 여러 선택지를 머릿속으로 시뮬레이션하고, 가장 좋아 보이는 것을 골라 행동한다. 연구진은 이 인간적 사고 과정을 컴퓨터에서 구현한 것이다. 실험 결과는 인상적이었다. 집안 잡동사니를 정리하는 랭알(LangR) 벤치마크에서 성공률이 65%에서 71%로 올랐고, 다양한 집안일을 평가하는 이비-알프레드(EB-ALFRED) 벤치마크에서는 44%에서 49%로 향상됐다. 가장 어려운 다중 객체 조작 과제에서는 상대적 개선폭이 36%에 달했다.
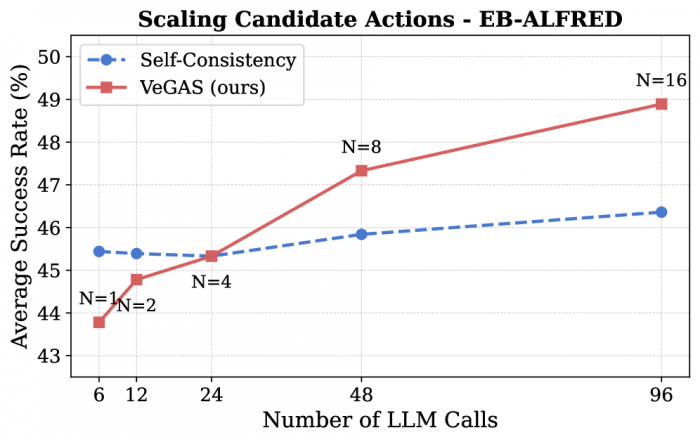
그림1. 후보 행동 증가에 따른 베가스와 단순 다수결 방식의 성능 비교
합성 실패 데이터, 검증 AI 학습의 비밀
검증 AI를 만들 때 가장 큰 문제는 "실패 사례"가 없다는 점이었다. 일반 데이터에는 성공 사례만 잔뜩 들어 있어, 어떤 행동이 잘못된 것인지 가르칠 자료가 부족했다. 연구진은 오픈AI(OpenAI)의 오쓰리(o3) 모델을 이용해 가짜 실패 사례를 인공적으로 만들어내는 방법을 고안했다. 성공한 행동 하나하나에 대해 "이 단계에서 만약 잘못된다면 어떤 실수를 할까"를 AI가 직접 상상해 만들어낸 것이다.
이렇게 만들어진 가짜 실패 데이터에는 잘못된 물체를 잡거나(바나나가 필요한데 사과를 가져옴), 잘못된 장소에 놓거나(침대에 놓아야 하는데 소파에 놓음), 필요한 사전 단계를 빼먹는(전자레인지를 열지 않고 켜려 함) 사례가 포함됐다. 검증 AI는 이런 실패 사례들과 함께 "왜 이게 틀렸는지" 설명까지 학습했기 때문에, 실제 상황에서도 비슷한 실수를 정확히 짚어낼 수 있다. 흥미로운 점은 이 검증기를 그냥 똑똑한 기성 모델로 대체했을 때는 효과가 전혀 없었다는 사실이다. 즉, '검증 전용 훈련'이 핵심이었다.
작은 AI가 큰 AI를 코치하는 시대, 모델 크기 경쟁의 종말
베가스 연구가 던지는 가장 큰 충격은 30억 매개변수짜리 작은 검증 AI가 720억 매개변수짜리 거대 모델의 성능을 끌어올렸다는 점이다. 큰 모델은 그대로 두고 옆에 작은 검증기만 붙였더니 성공률이 30%에서 38%로 뛰었다. 약 8%포인트 차이로 보일 수 있지만, AI 업계에서 이 정도 향상은 일반적으로 수십 배 더 큰 모델로 갈아타야 얻을 수 있는 수치다. 이는 AI 성능 향상이 반드시 더 큰 모델 학습을 필요로 하지 않는다는 강력한 증거다.
또 한 가지 주목할 점은 처리 속도다. 후보 행동을 16개나 만들고 각각을 5번씩 검증한다고 하면 96배 더 많은 계산이 필요할 것 같지만, 모든 작업이 동시에 처리되기 때문에 실제 응답 시간은 3초에서 8초로 약 2.7배만 늘었다. 검증 단계 하나를 추가한 것치고는 부담이 크지 않다. 베가스는 가정용 로봇뿐 아니라 자율주행, 산업용 로봇, AI 에이전트 등 행동을 결정하는 모든 AI 시스템에 적용될 수 있다. 첫 번째로 떠오른 답을 의심하는 AI, 그 작은 변화가 AI 산업의 흐름을 바꿀 가능성이 있다.
FAQ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. 베가스(VeGAS)는 일반 사용자도 곧 경험할 수 있는 기술인가요?
A1. 베가스는 현재 연구 단계의 기법이지만 작동 원리는 단순해 응용 범위가 넓습니다. 챗봇이 답변을 내놓기 전에 여러 후보를 만들고 스스로 검증하는 방식은 이미 일부 서비스에 도입되고 있어, 가까운 시일 내에 더 많은 AI 서비스에서 비슷한 '두 번 생각하기' 기능을 만나볼 수 있을 것으로 예상됩니다.
Q2. AI가 자기 실수를 잡아낸다면 사람의 감독은 더 이상 필요 없나요?
A2. 그렇지 않습니다. 베가스의 검증 AI도 합성 실패 데이터로 학습됐기 때문에 데이터에 없는 새로운 유형의 실수는 놓칠 수 있습니다. 또한 AI가 검증 AI의 판단을 무조건 따른다는 점에서, 검증 AI 자체에 편향이 있으면 그 편향이 그대로 전달될 위험도 있습니다. 사람의 최종 점검은 여전히 필요합니다.
Q3. 큰 모델을 키우는 대신 검증기를 붙이는 방식이 정말 효율적인가요?
A3. 베가스 실험에서는 30억 매개변수 검증기를 붙인 작은 모델이 720억 매개변수 모델과 비슷하거나 더 나은 성능을 보였습니다. 단, 매 행동마다 추가 계산이 필요해 응답 시간이 길어질 수 있고, 모든 작업에 검증이 필요한 것은 아니어서 작업 성격에 따라 적합한 방식이 다를 수 있습니다.
기사에 인용된 리포트 원문은 arXiv에서 확인할 수 있다.
리포트명: Think Twice, Act Once: Verifier-Guided Action Selection For Embodied Agents
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. (☞ 기사 원문 바로가기)
AI 리포터 (Aireporter@etnews.com)

