







2010년대 인공지능(AI) 연구가 딥러닝 시대에 들어선 이후, AI 모델 학습 연산량이 매년 4배씩 증가한 것으로 나타났다. 반도체 발전 지표가 되는 '무어의 법칙'을 압도하는 속도다. 2016년 이세돌과 역사적 대결의 주인공인 알파고 대비 최신 AI 모델의 연산량은 약 26만배나 증가했다. 천문학적 자본 투입과 알고리즘 혁신이 AI 발전 가속화를 이끌고 있다.
8일 미국 비영리 AI 연구기관 에포크AI에 따르면 2010년 이후 주요 AI 모델(총 443개) 학습에 투입된 연산량(FLOP·플롭)은 최근까지 모델당 연 평균 4.4배씩 성장했다. 연간 성장률만 비교해도 18~24개월마다 반도체 성능이 2배가 된다는 '무어의 법칙' 보다 8배 이상 빠른 속도다.
2010년대 '딥러닝 시대'의 문을 연 '알렉스넷(2012년 공개)'의 학습 연산량은 10의 17승 수준이었다. 2016년 이세돌 9단과 대국했던 딥마인드의 '알파고 리'의 연산량은 10의 21승 규모로 발전했다.
현재 기술 진보를 주도하는 최신 모델 연산량은 10의 25승에서 10의 26승 규모를 넘어선다. xAI가 지난해 공개한 '그록4'는 10의 26승 플롭스 규모 연산량을 사용한 것으로 추정된다.
단순 계산해도 딥러닝 혁명이 시작된 이후 AI 학습 연산량이 10억배 폭증한 것이다. 10년 전 이세돌을 이겼던 알파고 리와 최신 모델을 비교하면 연산량이 약 26만배 증가했다.
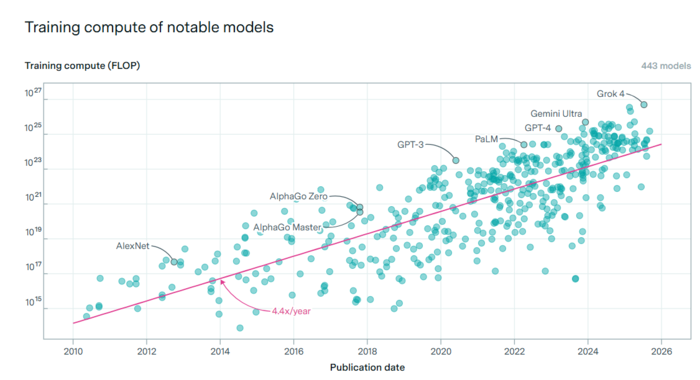
AI 모델 학습 연산량은 AI 성능을 결정하는 핵심 투입 자원이다. AI 성능은 모델 규모, 학습 데이터 규모, 연산량 등 요소로 설명된다. 이 가운데 연산량은 모델이 데이터를 실제 학습하는 역할을 한다.
이러한 성장은 하드웨어 성능 향상뿐만 아니라 천문학적 자본 투입을 통한 컴퓨팅 파워 증가와 알고리즘 혁신이 복합 작용한 결과로 풀이된다. 실제 10년 전 알파고 학습 비용은 약 수십억원 수준으로 추정되지만 현재 최신 모델 학습에 수조원 단위 컴퓨팅 비용이 투입되고 있다.
최재식 KAIST 교수(AI 예측 서비스 기업 인이지 대표)는 “AI 학습 연산량 급증은 차세대 AI 모델의 성능 개선을 위한 학습을 확대해온 결과”라면서 “개인용 AI 슈퍼컴퓨터 내 그래픽처리장치(GPU) 하나로 거대언어모델(LLM)을 구동할 수 있고 2개를 붙이면 AI 학습이 가능한 수준이 됐다”며 계속된 인프라 발전도 AI 학습 증가를 이끈 핵심 요인 중 하나라고 설명했다.
최근 AI 기술 경쟁은 단순 자원 투입량을 늘리는 것이 아니라 같은 연산량으로 훨씬 효율적인 성능을 내는 알고리즘 혁신 경쟁으로 옮겨가고 있다.
소재 특화 AI 기업 카이로스랩 나준채 대표는 “(10년 전과 비교했을 때)연산량 26만 배 증가는 AI가 인간의 지적 작업 전반을 다루는 범용 지능으로 진화하는 데 투입된 자원의 규모를 상징적으로 보여준다”면서 “지난 10년이 '연산량의 시대'였다면 앞으로의 10년은 에이전트 AI, 로보틱스 등 '효율과 자율성의 시대'가 될 것”이라고 내다봤다.
정현정 기자 iam@etnews.com, 박종진 기자 truth@etnews.com


