






멀티모달 AI 에이전트가 멈춰서는 곳은 어려운 추론이 아니다. 처음에 화면을 제대로 못 보는 순간이다. Z.ai와 칭화대(Tsinghua University) 연구진이 2026년 5월 공개한 GLM-5V-Turbo 기술 보고서는 추론을 강화해야 더 똑똑한 AI가 만들어진다는 업계의 통념을 정면으로 뒤집었다. 멀티모달 AI 에이전트(Multimodal AI Agent)란 글뿐 아니라 이미지, 영상, 화면, 문서까지 직접 보고 판단해 작업을 수행하는 인공지능을 말한다. 어떤 AI 모델을 골라야 일을 제대로 시킬 수 있는지를 가르는 핵심 기준이 바뀌었다는 신호다.
추론보다 인식이 멀티모달 AI의 상한선을 결정한다
GLM-5V-Turbo 보고서는 멀티모달 AI의 성능 한계가 고차원 추론이 아니라 기본 인식(Perception)에서 결정된다고 결론지었다. 인식이란 모델이 이미지나 화면을 얼마나 정확하게 보고 이해하는지를 뜻하는 개념이다. 연구팀은 "고급 추론처럼 보이는 실패의 대부분은 모델이 환경을 충분히 정확하게 보지 못하는 데서 시작된다"고 명시했다. 가장 강력한 멀티모달 모델조차 글자 미세 인식이나 공간 관계 파악에서 자주 틀리고, 이 오류가 추론과 의사결정, 실행으로 그대로 전파된다는 것이다. GUI 에이전트가 화면의 버튼을 잘못 누르는 일도 결국 버튼이 어디 있는지를 정확히 못 봤기 때문에 발생한다.
이 관점은 그동안 업계가 "더 깊은 추론"과 "더 긴 사고 사슬(Chain of Thought)"에 집중해온 흐름과 거리를 둔다. 연구진은 인식을 한 번 해결하고 넘어가는 저수준 모듈이 아니라, 고차원 멀티모달 능력의 천장 자체를 결정하는 토대로 봐야 한다고 주장했다. 모델을 평가할 때 추론 점수만 보지 말고 "이 모델이 화면을 얼마나 정확하게 보는가"를 먼저 따져야 한다는 실용적 함의가 따라온다.
디자인을 코드로 바꾸는 능력 94.8점, 클로드 오퍼스 4.6의 77.3점 압도
GLM-5V-Turbo는 디자인 이미지를 웹 코드로 변환하는 Design2Code 벤치마크에서 94.8점을 기록해 클로드 오퍼스(Claude Opus) 4.6의 77.3점, Kimi K2.5의 91.3점을 모두 앞섰다. Design2Code는 디자인 시안 한 장만 보여주고 똑같이 작동하는 HTML 코드를 만들어내라는 시험으로, 시각 정보를 코드로 옮기는 능력을 측정한다. 멀티모달 검색에서도 격차가 분명하다. MMSearch에서 72.9점(Claude Opus 4.6은 63.8점), 시각 정보가 핵심인 사실 질문 평가 SimpleVQA에서 78.2점(63.2점), 핵심 정보를 시각적으로 찾아내는 V*에서 89.0점(66.5점)을 받았다.
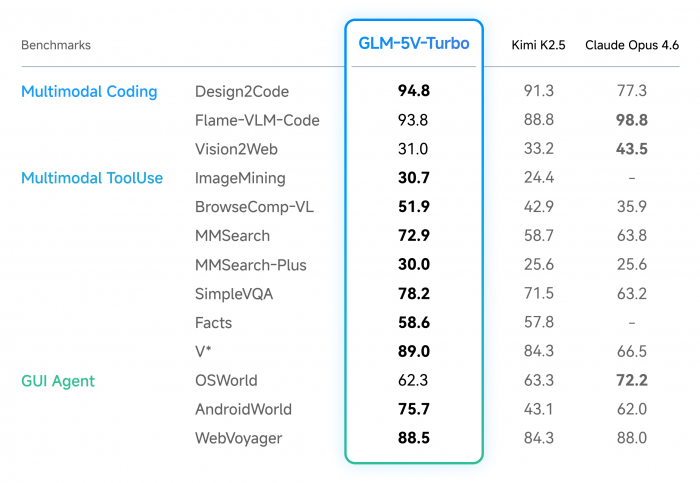
그림1. 멀티모달 코딩·도구 사용·GUI 에이전트 벤치마크에서 GLM-5V-Turbo와 Kimi K2.5, Claude Opus 4.6 성능 비교
특히 주목할 만한 변화는 이전 세대 GLM-4.6V와 비교했을 때 나타난다. 복잡한 멀티모달 탐색 능력을 평가하는 MMSearch-Plus에서 30.0점을 받아 이전 세대보다 약 8배 향상됐다. 점수 자체보다 의미 있는 것은 이 격차가 누적된 결과다. 한 번의 작업에서 7~8%의 정확도 차이가 매일 수십 차례 반복되는 에이전트 작업에 쌓이면, 며칠 뒤에는 전혀 다른 수준의 결과물이 나온다. 안드로이드 환경에서 자동으로 작업을 수행하는 AndroidWorld에서 75.7점(Claude Opus 4.6 62.0점)을 받은 것도 같은 흐름이다. GUI 에이전트가 화면을 잘 봐야 잘 누르고, 잘 누르는 능력이 곧 업무 완수율로 이어진다.
CogViT와 멀티모달 MTP로 본 능력의 구조
GLM-5V-Turbo가 인식 능력에서 격차를 벌린 핵심에는 CogViT라는 새로운 비전 인코더(Vision Encoder)가 있다. 비전 인코더란 이미지를 모델이 이해할 수 있는 숫자 표현으로 바꾸는 부품이다. CogViT는 4억 300만 개의 파라미터로 짜였으면서도 SigLIP2(4억 2700만)나 DFN-H(6억 3200만) 같은 더 큰 모델들과 ImageNet, CLIP 벤치마크에서 비등하거나 앞서는 성능을 냈다. 두 단계 학습 방식이 비결이다. 1단계에서는 이미지의 일부를 가린 채 복원하도록 시키며 시각 표현을 강화하고, 2단계에서는 80억 개의 중·영(중국어·영어) 이미지 텍스트 쌍으로 시각과 언어를 같은 의미 공간에 정렬했다.
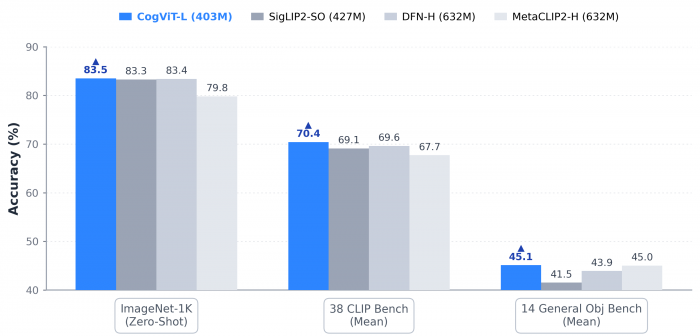
그림2. 일반·세부 멀티모달 과제 전반에서 CogViT와 최신 비전 인코더들의 성능 비교 그래프
연구팀은 멀티모달 다중 토큰 예측(Multimodal Multi-Token Prediction, MMTP)이라는 새로운 학습 구조도 도입했다. 다중 토큰 예측이란 모델이 한 단어씩이 아니라 여러 단어를 한꺼번에 예측하도록 학습시켜 속도와 정확성을 높이는 방식이다. 멀티모달로 확장하려면 이미지 토큰을 어떻게 다룰지가 문제가 되는데, 연구진은 세 가지 후보를 비교한 끝에 모든 이미지 토큰을 <|image|>라는 공유 학습 토큰으로 대체하는 방식을 택했다. 직접 이미지 임베딩을 흘려보내는 방식보다 학습 손실이 더 낮고 안정적으로 수렴했기 때문이다. 시각 정보의 분포가 텍스트와 크게 다르기 때문에, 가벼운 예측 모듈이 이를 그대로 흡수하기 어렵다는 설명이다.
또한 GLM-5V-Turbo는 30개 이상의 과제 범주에서 강화학습(Reinforcement Learning, RL)을 한 번에 진행했다. 2D 이미지 그라운딩에서 4.8%, 영상 이해에서 5.6%, 3D 그라운딩에서 7.7%, OCR에서 4.2%씩 지도학습 대비 향상된 결과가 나왔다. 흥미로운 점은 한 영역에서 익힌 사고 패턴이 다른 영역으로 옮겨갔다는 것이다. 단일 화면을 코드로 바꾸는 학습이 여러 단계로 이뤄진 복잡한 코딩 능력 향상으로 이어졌다. 연구진은 이를 멀티태스크 강화학습이 단순한 능력 합산이 아니라 "전략 패턴의 더 깊은 공유"를 만들어낸다고 해석했다.
클로드 코드와 결합한 화면을 보는 에이전트
GLM-5V-Turbo는 Claude Code, AutoClaw, OpenClaw 등 외부 에이전트 프레임워크에 직접 연결돼 화면을 보고 작업하는 시스템으로 작동한다. 클로드 코드(Claude Code)는 앤트로픽(Anthropic)이 만든 코딩용 에이전트 도구이고, 오토클로(AutoClaw)는 브라우저와 GUI 자동화를 담당하는 도구다. 이 결합에서 GLM-5V-Turbo가 맡는 역할은 두뇌에 해당한다. 화면을 보고 다음에 무엇을 해야 할지 판단해 손에 해당하는 도구에 작업을 넘기는 구조다. PinchBench에서 87.0/80.7점, ClawEval에서 57.7/75.0점, ZClawBench에서 57.6점을 기록해 멀티모달 능력이 단순 벤치마크 점수에 그치지 않고 실제 업무 수행에서도 작동한다는 점이 확인됐다.
연구진은 ImageMining이라는 자체 벤치마크도 함께 공개했다. 이미지를 단순히 묘사하게 하는 기존 시각 질의응답(VQA)과 달리, 모델이 이미지의 일부를 잘라내거나 확대해 추가 검색 단서로 활용하게 만든 도구 호출 능력 평가다. 217개 사례로 구성됐고 인물·장소·자연·과학 등 7개 영역을 다룬다. 이 벤치마크가 강조하는 능력은 "이미지로 생각하고, 이미지로 깊이 검색한다(Think with image, deep search with image)"는 개념이다. 사진 한 장에서 인물을 식별하고, 그 인물이 등장한 영화 포스터를 검색하고, 거기서 다시 다른 정보로 넘어가는 식의 멀티홉(multi-hop) 추론을 요구한다. 정적 입력이 아니라 상호작용 가능한 환경으로 이미지를 다루는 방식이다.
FAQ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. 멀티모달 AI 에이전트와 일반 챗봇은 어떤 점이 다른가요?
일반 챗봇은 주로 글로 된 입력에 글로 답하지만, 멀티모달 AI 에이전트는 이미지, 영상, 웹페이지, GUI 화면을 직접 보고 그 위에서 작업을 수행합니다. 예를 들어 디자인 시안을 보여주면 그대로 웹사이트 코드를 만들어내거나, 안드로이드 화면을 보면서 앱을 자동으로 조작할 수 있는 것이 차이점입니다.
Q2. GLM-5V-Turbo는 Claude Opus 4.6보다 모든 면에서 뛰어난가요?
그렇지는 않습니다. 디자인을 코드로 변환하는 Design2Code(94.8 vs 77.3), 멀티모달 검색 MMSearch(72.9 vs 63.8), 안드로이드 화면 조작 AndroidWorld(75.7 vs 62.0) 등에서는 GLM-5V-Turbo가 앞섭니다. 반면 텍스트 전용 코딩 벤치마크 CC-Backend(22.8 vs 26.9), 운영체제 환경 OSWorld(62.3 vs 72.2), 일부 클로(Claw) 평가에서는 Claude Opus 4.6가 더 높습니다.
Q3. CogViT라는 비전 인코더가 왜 중요한가요?
비전 인코더는 AI가 이미지를 이해하기 전 첫 번째 단계로 이미지를 숫자 정보로 바꾸는 부품입니다. 이 부품이 얼마나 정확한지가 모델의 시각 인식 한계를 결정합니다. CogViT는 더 큰 인코더들과 비슷한 성능을 4억 300만 개 파라미터로 달성해, 효율과 정확성을 동시에 추구한 사례로 평가됩니다.
기사에 인용된 리포트 원문은 arXiv에서 확인할 수 있다.
리포트명: GLM-5V-Turbo: Toward a Native Foundation Model for Multimodal Agents (Z.ai & Tsinghua University, 2026)
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. (☞ 기사 원문 바로가기)
AI 리포터 (Aireporter@etnews.com)

