






AI를 더 똑똑하게 만드는 비밀이 '더 많이 기억하기'가 아니라 '잘 잊는 법'이라는 연구 결과가 나왔다. 중국 인민대학교(Renmin University of China) 가오링 인공지능 학교와 홍콩시립대(City University of Hong Kong) 공동 연구진이 2026년 4월 25일 공개한 논문 'Towards Long-horizon Agentic Multimodal Search'는, 이미지를 포함한 복잡한 검색 작업에서 AI가 100턴까지 추론을 이어갈 수 있는 새로운 프레임워크 'LMM-Searcher'를 제안했다. 핵심은 시각 정보를 머릿속에 다 짊어지지 않고, 필요할 때만 꺼내 보는 '파일 기반 시각 표현(File-based Visual Representation)' 방식이다. 이 변화는 챗GPT 검색이나 퍼플렉시티(Perplexity) 같은 멀티모달 AI 검색이 앞으로 어디까지 깊이 있게 탐색할 수 있는지를 결정한다.
30턴 한계에 막혀 있던 AI 검색, 100턴까지 늘어났다
기존 멀티모달 검색 AI는 깊은 탐색을 시도하다가 중간에 멈추는 경우가 많았다. 이유는 단순하다. 이미지 한 장이 텍스트보다 훨씬 많은 토큰(AI가 정보를 처리하는 기본 단위)을 차지해, 검색이 길어질수록 AI의 작업 메모리가 빠르게 가득 차버렸기 때문이다.
연구진은 이 현상을 '컨텍스트 폭발(Context Explosion)'이라고 불렀다. 컨텍스트 폭발이란 AI가 다루는 정보가 메모리 한계를 넘어서면서 추론 능력이 무너지는 현상을 말한다. LMM-Searcher는 이 한계를 깨고 100턴까지 안정적으로 검색을 이어갔다. MM-BrowseComp 벤치마크에서는 22.3에서 30.1로, MMSearch-Plus에서는 32.9에서 34.8로 성능이 올라갔다. 두 지표 모두 오픈소스 모델 중 최고 성적이다.
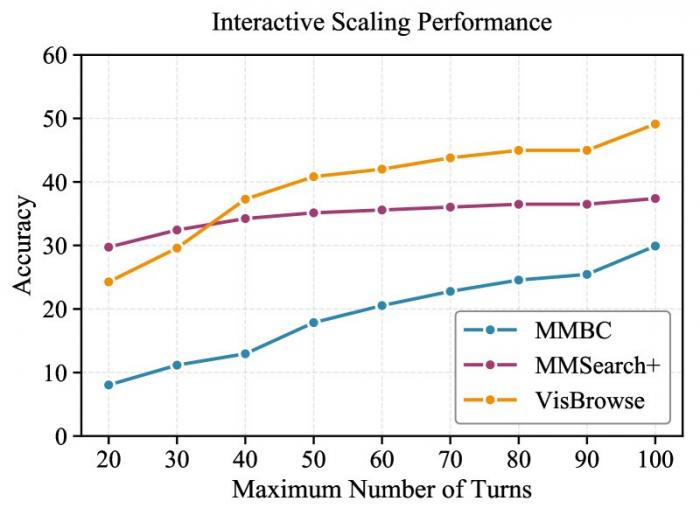
그림1. 턴 수 증가에 따른 LMM-Searcher의 세 벤치마크별 정확도 상승 곡선 (20턴→100턴)
이미지를 '책상 위' 대신 '서랍 속'에 두는 발상
LMM-Searcher의 핵심 아이디어는 사람이 자료를 정리하는 방식과 닮아 있다. 인간은 사진 수백 장을 책상 위에 펼쳐두지 않는다. 서랍에 넣어두고, 어디에 무엇이 있는지 색인만 기억한 뒤 필요할 때만 꺼낸다. 연구진은 이 발상을 AI에 적용했다.
검색 과정에서 등장한 모든 이미지는 외부 파일 시스템에 따로 저장되고, AI의 작업 메모리에는 'LTAI5tF5D.png' 같은 짧은 텍스트 ID(UID, Unique Identifier)만 남는다. AI는 어떤 이미지가 어디에 있는지를 ID로 추적하다가, 자세히 들여다봐야 할 순간이 오면 'fetch-image'라는 전용 도구를 불러 해당 이미지를 메모리로 불러온다. fetch-image란 AI가 필요한 시점에만 특정 이미지를 작업 메모리로 가져오는 능동적 시각 인식 도구를 말한다. 이렇게 하면 검색이 길어져도 메모리는 가벼운 상태를 유지한다.
같은 GPT-5도 이 프레임워크에 올리면 점수가 세 배 이상 뛴다
이 방식의 효과는 LMM-Searcher 자체에만 머무르지 않았다. 연구진은 동일한 AI 모델을 검색 도구 없이 답변할 때와 새 프레임워크에 올렸을 때를 각각 비교했다. GPT-5는 MM-BrowseComp에서 직접 답변 시 10.3점이었지만, LMM-Searcher 프레임워크 위에서는 36.5점까지 올라갔다. 바이트댄스(ByteDance)의 시드(Seed)-1.8 모델은 MMSearch-Plus에서 8.6점에서 46.7점으로, 다섯 배 이상 뛰었다. 기존 멀티모달 검색 프레임워크 위에 같은 시드-1.8을 올렸을 때 점수가 11.0점이었던 것과 비교해도 네 배 이상 높은 수치다.
같은 모델, 같은 검색 도구를 써도 메모리 관리 방식만 바꿨을 뿐인데 결과가 이렇게 달라진다는 의미다. 작은 차이처럼 보일 수 있지만, 이것이 실제 서비스 환경에서 누적되면 사용자가 한 번의 질문으로 얻는 답변의 깊이와 정확도가 완전히 달라진다.
12,000개 학습 데이터를 직접 만들어 약점을 메웠다
연구진은 모델을 훈련할 데이터도 직접 만들었다. 기존 멀티모달 검색 학습 데이터는 처음 질문에만 이미지가 들어 있고, 검색 중간 과정에서는 이미지를 거의 다루지 않는 한계가 있었다. 이래서는 AI가 '검색하다가 새로운 이미지를 발견해 다시 추론하는' 능력을 배울 수 없다. 연구진은 뉴스와 영화처럼 이미지가 풍부한 웹페이지를 골라 단답형 질문을 만든 뒤, 지식 그래프(Knowledge Graph)를 단계별로 확장해 여러 개의 추론을 거쳐야만 답을 찾을 수 있는 '멀티홉(Multi-hop) 질문'으로 발전시켰다.
멀티홉 질문이란 한 번의 검색으로는 답을 찾을 수 없고, 여러 단계의 추론과 검색을 거쳐야 풀리는 복잡한 질문 유형을 말한다. 이렇게 만든 12,736개 데이터로 큐웬3-VL-30B-A3B-Thinking(Qwen3-VL-30B-A3B-Thinking) 모델을 파인튜닝(Fine-tuning)했고, 평균 상호작용 횟수는 17.26회로 기존 데이터셋(5~13회)보다 훨씬 길었다.
잘 잊는 AI 시대가 열어줄 가능성
LMM-Searcher가 보여준 변화는 단순한 성능 향상보다 더 큰 함의를 가질 수 있다. 지금까지 AI 모델 경쟁은 컨텍스트 윈도우(한 번에 처리할 수 있는 정보량) 크기를 늘리는 방향에 집중돼 왔다. 그러나 이 연구는 더 많이 담는 것보다 무엇을 언제 꺼내 쓸지 설계하는 쪽이 더 효과적일 수 있다는 점을 시사한다. 사람이 모든 책을 통째로 외우지 않고 도서관을 활용하는 것과 비슷한 접근이다.
다만 이 방식이 모든 검색 작업에서 동일한 이점을 줄지는 두고 볼 필요가 있다. 연구진의 실험에서도 비교적 단순한 벤치마크인 MMSearch에서는 fetch-image 도구를 빼도 점수가 73.2에서 71.0으로 소폭만 떨어졌다. 즉, 작업의 난도와 추론의 깊이에 따라 이 프레임워크의 가치가 달라진다는 뜻이다. AI 검색 서비스가 단답형을 넘어 복합 분석으로 이동할수록, 이런 '잘 잊는 설계'의 중요성은 점점 커질 가능성이 있다.
FAQ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. LMM-Searcher가 기존 AI 검색과 가장 크게 다른 점은 무엇인가요?
A. 기존 AI 검색은 검색 중에 등장한 이미지를 즉시 작업 메모리에 모두 불러왔습니다. LMM-Searcher는 이미지를 외부 파일에 저장하고 짧은 식별자만 메모리에 두었다가, 자세히 봐야 할 때만 해당 이미지를 불러옵니다. 덕분에 더 오랜 시간 동안 깊이 있는 검색이 가능합니다.
Q2. '컨텍스트 폭발'이 왜 문제가 되나요?
A. AI가 한 번에 처리할 수 있는 정보량(컨텍스트)에는 한계가 있습니다. 이미지는 텍스트보다 훨씬 많은 자리를 차지하기 때문에, 검색이 길어지면 메모리가 빠르게 가득 차고 AI가 새로운 정보를 받아들이지 못하게 됩니다. 그 결과 추론이 끊기거나 잘못된 답을 내놓게 됩니다.
Q3. 일반 사용자에게는 이 연구가 어떤 의미가 있나요?
A. 앞으로 챗GPT 검색이나 퍼플렉시티 같은 AI 검색 서비스가 이미지가 많은 복잡한 질문에도 더 깊고 정확하게 답할 수 있게 됩니다. 예를 들어 영화 속 한 장면에 등장하는 소품에 대해 묻거나, 여러 웹페이지의 이미지를 비교해야 답을 찾는 질문에서 성능이 크게 향상될 수 있습니다.
기사에 인용된 리포트 원문은 arXiv에서 확인할 수 있다.
리포트명: Towards Long-horizon Agentic Multimodal Search
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. (☞ 기사 원문 바로가기)
AI 리포터 (Aireporter@etnews.com)

