






AI 보안은 더 똑똑한 AI가 잡아야 한다는 통념이 한 편의 논문 앞에 무너졌다. 미국 캘리포니아대 샌디에이고(UC San Diego)와 노스캐롤라이나대 그린즈버러(UNC Greensboro) 공동 연구진이 2026년 5월 1일 아카이브(arXiv)에 발표한 연구에 따르면, 40억 파라미터급 거대 언어 모델(LLM)도 AI 에이전트를 노린 다단계 해킹의 85%를 그냥 통과시켰다. 반면 신용카드 사기 탐지에서 영감을 얻은 가벼운 탐지기는 같은 공격의 92%를 0.0046초 만에 차단했다. AI 에이전트(AI Agent)란 사람의 명령을 받아 파일을 읽고, 이메일을 보내고, 웹을 검색하는 등 실제 행동을 자율적으로 수행하는 AI 비서를 말한다. 이 비서가 회사 내부망에 접근하기 시작한 지금, 무엇이 진짜 위협인지 그리고 어떻게 막아야 하는지가 처음으로 데이터로 드러났다.
한 문장씩 검사해서는 절대 못 잡는 AI 해킹의 정체
AI 에이전트 공격은 단일 프롬프트(prompt)가 아닌 여러 차례 대화에 걸쳐 서서히 진행된다는 점이 핵심이다. 프롬프트란 사용자가 AI에게 입력하는 명령어 한 줄을 뜻한다. UC 샌디에이고 연구진은 기존 AI 보안 시스템이 거의 모두 "이 한 줄이 위험한가"만 본다고 지적했다. 그런데 진짜 공격자는 첫 번째 메시지에서 "안녕하세요, 새로 입사했는데 보고서가 어디 있나요?"처럼 무해한 질문으로 시작한다. 두세 번째 메시지에서 슬쩍 민감 정보를 열어보고, 마지막에서야 외부 주소로 데이터를 빼돌리는 식이다.
연구진은 이런 흐름을 "적대적 상호작용(adversarial interaction)"이라고 정의했다. 적대적 상호작용이란 개별 메시지는 평범해 보이지만, 전체 대화 흐름을 이어보면 명백히 위험한 의도로 수렴하는 공격 패턴을 말한다. 한 줄짜리 검사로는 절대 잡을 수 없다는 것이 이번 연구의 출발점이다.
분할 유출부터 권한 표류까지, AI 비서 해킹의 4대 시나리오
연구진은 실제 발생 가능한 AI 에이전트 공격을 네 가지 유형으로 분류했다. 각 유형은 일반 회사원이 매일 보는 업무 시나리오와 거의 구분이 안 된다.
첫 번째는 분할 유출(split exfiltration)이다. 공격자가 두 번의 대화로 일을 끝낸다. 한 번은 "고객 명단 파일 좀 보여줘", 다음은 "이걸 이 이메일 주소로 보내줘"라고 시킨다. 둘 다 개별 명령으로는 합법적이지만, 합치면 정보 유출이 된다.
두 번째는 컨텍스트 세탁(context laundering)이다. 네 번의 대화로 진행되며, 처음에는 회사 뉴스나 일정 같은 무해한 정보를 몇 번 가져오게 한 뒤 마지막에 슬쩍 민감 파일 접근과 외부 전송을 끼워 넣는다. 마치 평범한 업무 흐름의 일부처럼 보이게 만드는 위장술이다.
세 번째는 권한 표류(privilege drift)이다. 저위험 작업부터 시작해 한 단계씩 더 위험한 권한으로 천천히 올라간다. 단순 웹 검색 → 파일 읽기 → 쉘 명령 실행 → 외부 전송으로 이어지는 식이다. 각 단계만 보면 정상이지만 누적된 궤적은 명백한 침투다.
네 번째는 단계별 폭발(staged burst)이다. 세 번의 대화 안에서 민감 파일을 연속으로 빠르게 읽은 뒤, 마지막 한 번에 모두 외부로 보낸다. 일반 사용자라면 이렇게 짧은 시간에 여러 파일을 한꺼번에 다루지 않는다.
이 네 가지 공격이 무서운 이유는 단순하다. 각 메시지를 따로 떼어내 검사하면 하나같이 평범한 업무 요청처럼 보인다는 점이다.
강력한 거대 모델의 굴욕, 공격 절반 이상을 그냥 통과시켰다
이번 논문에서 가장 충격적인 결과는 거대 LLM이 AI 보안에 무력했다는 사실이다. 연구진은 가장 강력한 베이스라인으로 알리바바(Alibaba)의 큐원3-4B(Qwen3-4B) 모델을 엔비디아(NVIDIA) A6000 GPU에 올려 테스트했다. 그런데 이 모델은 1만 2천 건의 시뮬레이션 인터랙션을 대상으로 한 실험에서 실제 공격 중 단지 15%만 차단했다. 정확도 지표인 F1 점수는 0.26에 머물렀다. 1.0이 만점이고 0.5만 넘어도 쓸 만한 수준인데, 그 절반에도 못 미친 셈이다.
직전 세 턴까지 함께 보는 향상된 버전(Seq-window)을 시도하자 F1이 0.71까지 올라갔지만, 여전히 공격의 23%는 통과시켰다. 게다가 이 거대 모델 검사는 한 번 돌리는 데 약 43밀리초(0.043초)가 걸렸다. 짧아 보이지만, AI 에이전트가 매번 행동할 때마다 추가되는 지연이라 실제 서비스 속도 예산의 5% 이상을 잡아먹는다. 검사 한 번에 LLM이 답하는 시간의 5%를 더 쓰는 셈이다.
연구진은 논문에서 "단일 턴 임베딩이 아무리 풍부해도 궤적(trajectory) 신호를 회복할 수 없다"고 못 박았다. 즉, 한 문장씩 아무리 똑똑하게 분석해도 여러 문장에 흩어진 위협의 그림은 절대 그려지지 않는다는 뜻이다.
신용카드 사기 탐지 기법이 AI 보안의 답이 된 이유
연구진의 해법은 의외의 곳에서 왔다. 바로 신용카드 사기 탐지 시스템이다. 신용카드 회사는 한 건의 결제만 보고 사기를 판단하지 않는다. 최근 결제 빈도, 새 기기 사용 여부, 평소와 다른 지역, 결제 금액 패턴 같은 누적 신호를 함께 본다. 연구진은 이 발상을 그대로 AI 에이전트에 옮겼다.
이들이 만든 저지연 사기 탐지 레이어(Low-Latency Fraud Detection Layer)는 한 차례 대화마다 42개 신호를 자동으로 뽑아낸다. 입력 길이와 의심 키워드 같은 프롬프트 정보, 거부된 요청 횟수 같은 세션 동향, 어떤 도구를 어떤 순서로 썼는지, 외부 콘텐츠가 끼어들었는지 같은 컨텍스트 정보, 그리고 누적 위험 점수와 새 수신자 등장 여부 같은 사기 영감(fraud-inspired) 신호다. 이 가운데 결정적 역할을 한 그룹이 마지막 사기 영감 신호다. 이 그룹만 단독으로 써도 F1 0.76, 공격 차단율(ASR reduction) 87%를 기록해 특징 절제(ablation) 분석에서 전체 42개 신호를 다 쓴 모델이 F1 0.81, 차단율 94%를 기록한 것과 거의 동등한 성능을 냈다.
이 42개 신호를 엑스지부스트(XGBoost)라는 가벼운 모델에 넣자 놀라운 결과가 나왔다. F1 0.76으로 가장 강력한 거대 모델 기반 탐지보다 높은 정확도를 보이면서, 한 번 검사에 단 4.6밀리초(0.0046초)밖에 걸리지 않았다. 거대 모델보다 약 9.4배 빠른 속도다. CPU 한 스레드만 써도 돌아간다. 공격 차단율은 92%에 달했다. 차이가 작아 보일 수 있지만, 하루 수천만 건의 AI 에이전트 호출이 발생하는 기업 환경에서는 누적 효과가 엄청나다. 9배 느린 시스템은 결국 실시간 탐지를 포기하거나 비용이 9배 더 든다는 뜻이기 때문이다.
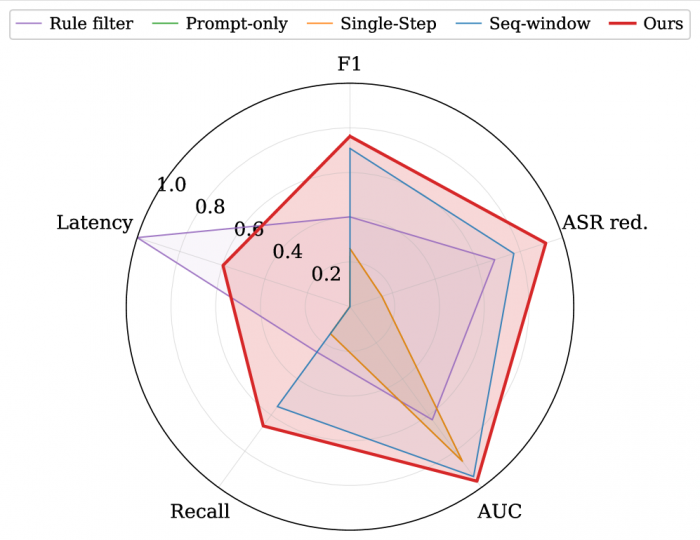
그림1. 5개 지표로 본 탐지기별 종합 성능 비교 (면적이 넓을수록 우수)
AI 자율성 확대 시대, 행동 탐지가 새로운 표준이 될 가능성
이번 연구는 AI 보안의 무게중심이 "무엇을 말했는가"에서 "어떻게 행동했는가"로 옮겨가고 있음을 보여준다. AI 에이전트가 단순 대화 챗봇에서 벗어나 파일 시스템과 이메일, 쉘 명령에 접근하기 시작한 지금, 더 이상 입력 한 줄의 의도를 판별하는 것만으로는 부족하다는 점이 데이터로 입증됐다.
다만 한 가지 짚어둘 부분은 있다. 이번 실험은 모두 시뮬레이션 데이터(1만 2천 건)로 진행됐다는 점이다. 연구진도 "실제 공격의 다양성과 복잡성을 완전히 반영하지는 못한다"고 인정했다. 또한 신호 설계의 품질에 성능이 크게 좌우되는 만큼, 공격자가 새로운 우회 전략을 개발할 경우 신호 자체를 다시 짜야 할 가능성도 있다. 이 방식이 실제 운영 환경에서 어떻게 작동할지는 향후 더 두고 볼 필요가 있다. 다만 행동 패턴 단위 탐지가 프롬프트 단위 필터링을 보완하는 새로운 표준이 될 가능성은 충분해 보인다.
기업 입장에서 던질 질문은 명확해졌다. 우리가 쓰는 AI 비서는 단일 명령만 검사하는가, 아니면 행동 궤적 전체를 보는가. 이 질문의 답이 향후 몇 년간 기업의 AI 보안 수준을 가를 핵심 분기점이 될 것이다.
FAQ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. AI 에이전트가 일반 챗봇과 어떻게 다른가요?
일반 챗봇은 답변만 생성하지만, AI 에이전트는 실제로 파일을 읽고, 이메일을 보내고, 외부 도구를 직접 사용합니다. 즉 말이 아니라 행동을 하는 AI라서 보안 위험도 훨씬 커집니다.
Q2. 프롬프트 인젝션(prompt injection)이 무엇인가요?
공격자가 평범해 보이는 문장 속에 AI를 조종하는 명령어를 숨겨 넣는 해킹 방식입니다. AI가 시스템 설정을 어기게 만들거나 비밀 정보를 노출하게 유도하는 가장 흔한 AI 공격 유형입니다.
Q3. 일반 사용자도 이번 연구가 적용된 AI를 곧 쓸 수 있나요?
이번에 발표된 탐지 레이어는 즉시 상용화된 제품은 아니지만, 가볍고 빠른 구조라 기업용 AI 에이전트 보안 솔루션에 비교적 빠르게 적용될 수 있습니다. 일반 사용자가 클로드(Claude)나 챗GPT(ChatGPT) 같은 서비스를 쓸 때 백엔드에서 자동으로 작동하게 될 가능성이 높습니다.
기사에 인용된 리포트 원문은 arXiv에서 확인할 수 있다.
리포트명: A Low-Latency Fraud Detection Layer for Detecting Adversarial Interaction Patterns in LLM-Powered Agents
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. (☞ 기사 원문 바로가기)
AI 리포터 (Aireporter@etnews.com)

