







SK텔레콤 대규모언어모델(LLM) 'A.X-K1'이 한국수학올림피아드(KMO) 문제 기반 평가에서 국내 독자 모델 가운데 가장 높은 성적을 기록했다. 동일 시점 글로벌 동급 모델과 비교해도 단일정답률에서 앞선 것으로 나타났다.
KAIST 전산학부 박노성 교수 연구팀은 최근 치러진 2026년 제40회 한국수학올림피아드 1차 시험 20문항으로 국내외 최신 LLM 11종의 수학 추론 능력을 평가한 결과 이같이 나타났다고 11일 밝혔다. 이번 평가는 최신 시험 문제를 사용해 학습 데이터 오염 가능성을 낮춘 것이 특징이다.
평가 결과 SK텔레콤 A.X-K1은 국내 독자 모델 중 가장 높은 단일정답률(pass@1) 83.75%를 기록했다. 8회 시도 중 한 번이라도 정답을 맞히는 pass@8은 89.94%, 다수결 정답률(majority vote)은 90%였다. 업스테이지 솔라는 pass@1 78.44%, LG AI연구원 엑사원은 75.94%를 기록했다.
연구팀은 작년 말 기준 공개된 글로벌 동급 모델과 비교할 때 A.X-K1이 단일정답률에서 앞섰다고 설명했다. 비교군인 알리바바 큐원3.5-397B-A17B는 82.50%, 문샷AI 키미 K2.5는 81.25%, 딥시크 V3.2는 79.38%였다.
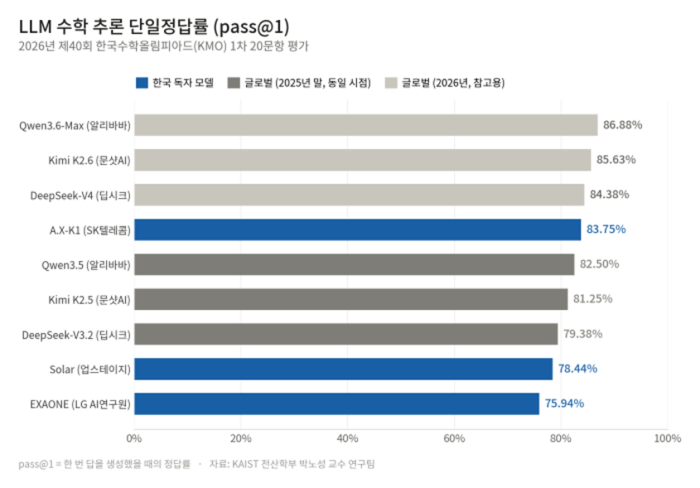
다만 올해 공개된 글로벌 최신 모델과 비교하면 격차는 남아 있었다. 큐원3.6-맥스-프리뷰는 86.88%, 키미 K2.6은 85.63%, 딥시크 V4-플래시는 84.38%를 기록했다. 연구팀은 이는 반년 이상 개발 시점 차이가 반영된 결과로 봤다.
문항별로는 19번 문제가 공통 난제로 나타났다. 평가 대상 11개 모델 모두 이 문항에서 정답률 0%를 기록했다. 연구팀은 경우 분석과 전역 제약 관리, 완전 탐색이 필요한 조합 문제에서 현재 LLM이 여전히 한계를 보였다고 분석했다.
연구팀은 이번 결과가 SK텔레콤을 포함한 국내 독자 파운데이션 모델이 수학 추론 분야에서 글로벌 경쟁력을 높이고 있음을 보여준다고 설명했다. 동시에 다음 단계는 모델 규모 확대보다 검증과 탐색, 증명을 결합한 시스템 설계가 될 것이라고 덧붙였다.
박 교수 연구팀은 “이번 결과는 한국 독자 AI 생태계가 글로벌 프런티어와의 격차를 좁히고 있음을 보여주는 한편, 다음 경쟁의 무대는 '더 큰 모델'이 아니라 '검산하고, 탐색하고, 증명하는 시스템'에 있다는 점을 시사한다”고 말했다.
남궁경 기자 nkk@etnews.com

